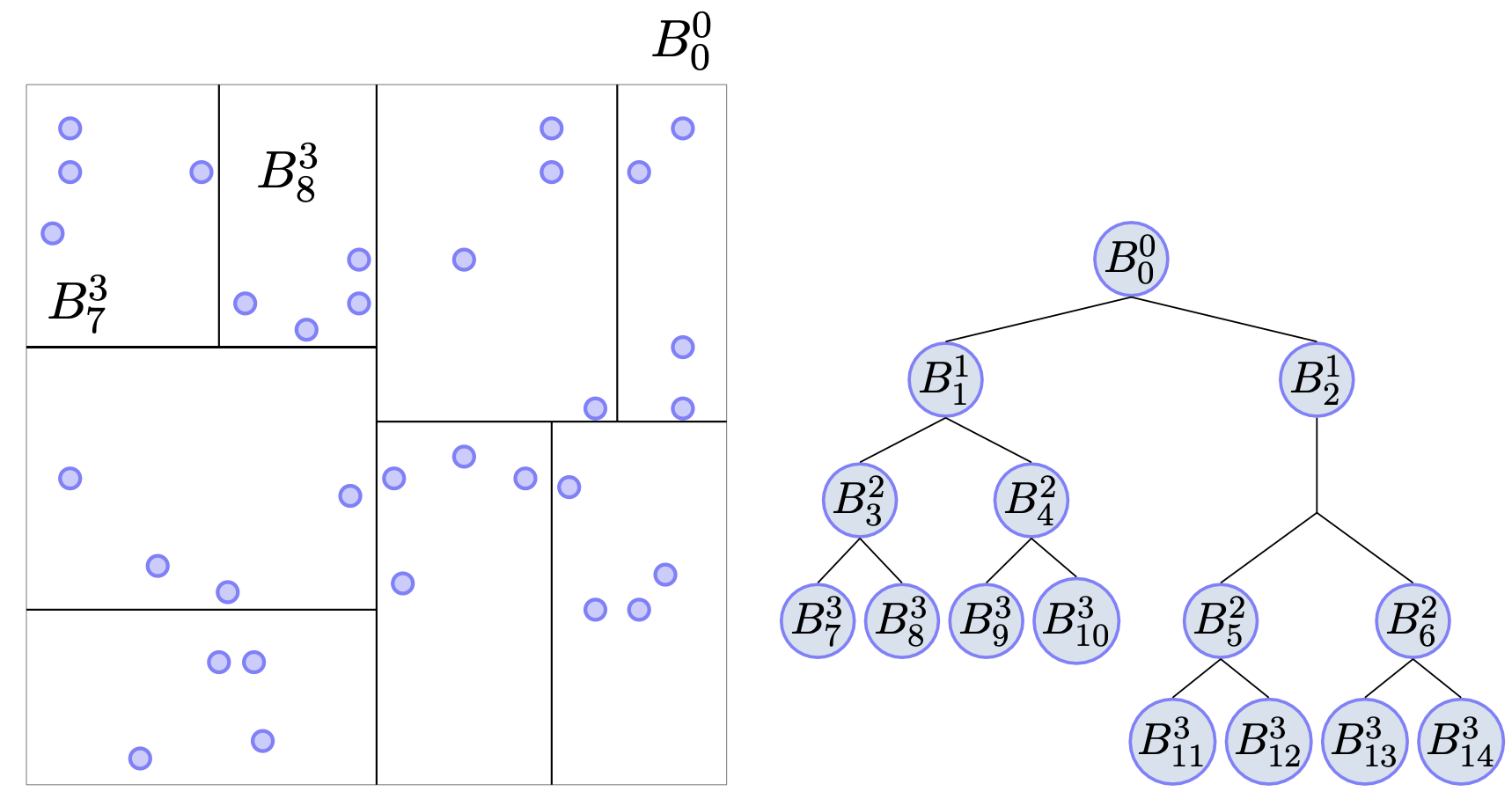
With the advent of massive data sets, much of the computational science and engineering community has moved toward data-intensive approaches in regression and classification. However, these present significant challenges due to increasing size, complexity, and dimensionality of the problems. In particular, covariance matrices in many cases are numerically unstable, and linear algebra shows that often such matrices cannot be inverted accurately on a finite precision computer. A common ad hoc approach to stabilizing a matrix is application of a so-called nugget. However, this can change the model and introduce errors to the original solution. It is well known from numerical analysis that ill-conditioned matrices cannot be accurately inverted. We develop a multilevel computational method that scales well with the number of observations and dimensions. A multilevel basis is constructed adapted to a kd-tree partitioning of the observations. Numerically unstable covariance matrices with large condition numbers can be transformed into well-conditioned multilevel ones without compromising accuracy. Moreover, it is shown that the multilevel prediction exactly solves the best linear unbiased predictor (BLUP) and generalized least squares (GLS) model, but is numerically stable.